Power Query traduce tus pasos a SQL y los empuja al servidor. Menos datos viajan, todo va más rápido.
Clic derecho en un paso → Ver consulta nativa (View Native Query).
Si está disponible → ese paso se pliega a SQL.
Si está en gris → se ejecuta en Power BI (no se pliega).
Meta: que filtros, selección de columnas y agrupaciones se plieguen al origen.
Pasos que pliegan vs que rompen
// PLIEGAN (se traducen a SQL):=Table.SelectRows(Origen, each [fecha_pedido] >= #date(2024,1,1))
=Table.SelectColumns(Origen, {"n_orden", "monto_usd"})
=Table.Group(Origen, {"producto_id"}, {{"m", eachList.Sum([monto_usd])}})
// ROMPEN el folding (déjalos al final o evítalos):=Table.AddColumn(Origen, "x", eachText.Reverse([cliente]))
=Table.Buffer(Origen)
Filtra y reduce columnas primero; lo no plegable, al final.
Empujar lógica a vistas SQL
En vez de transformar en M, expón vistas limpias en el origen. SunFruits ya trae vw_ventas.
CREATE VIEW sunfruits.vw_ventas ASSELECT v.n_orden, v.fecha_pedido, c.region, c.pais,
p.producto, p.categoria, v.cajas, v.kg_netos,
v.monto_usd, to_char(v.fecha_pedido,'YYYY-MM') AS periodo
FROM fact_ventas v
JOIN dim_cliente c ON c.cliente_id = v.cliente_id
JOIN dim_producto p ON p.producto_id = v.producto_id;
La vista se pliega y centraliza la lógica de negocio en la BD.
Agregaciones para DirectQuery
El problema
Sumar millones de filas en DQ por cada visual es lento.
La solución
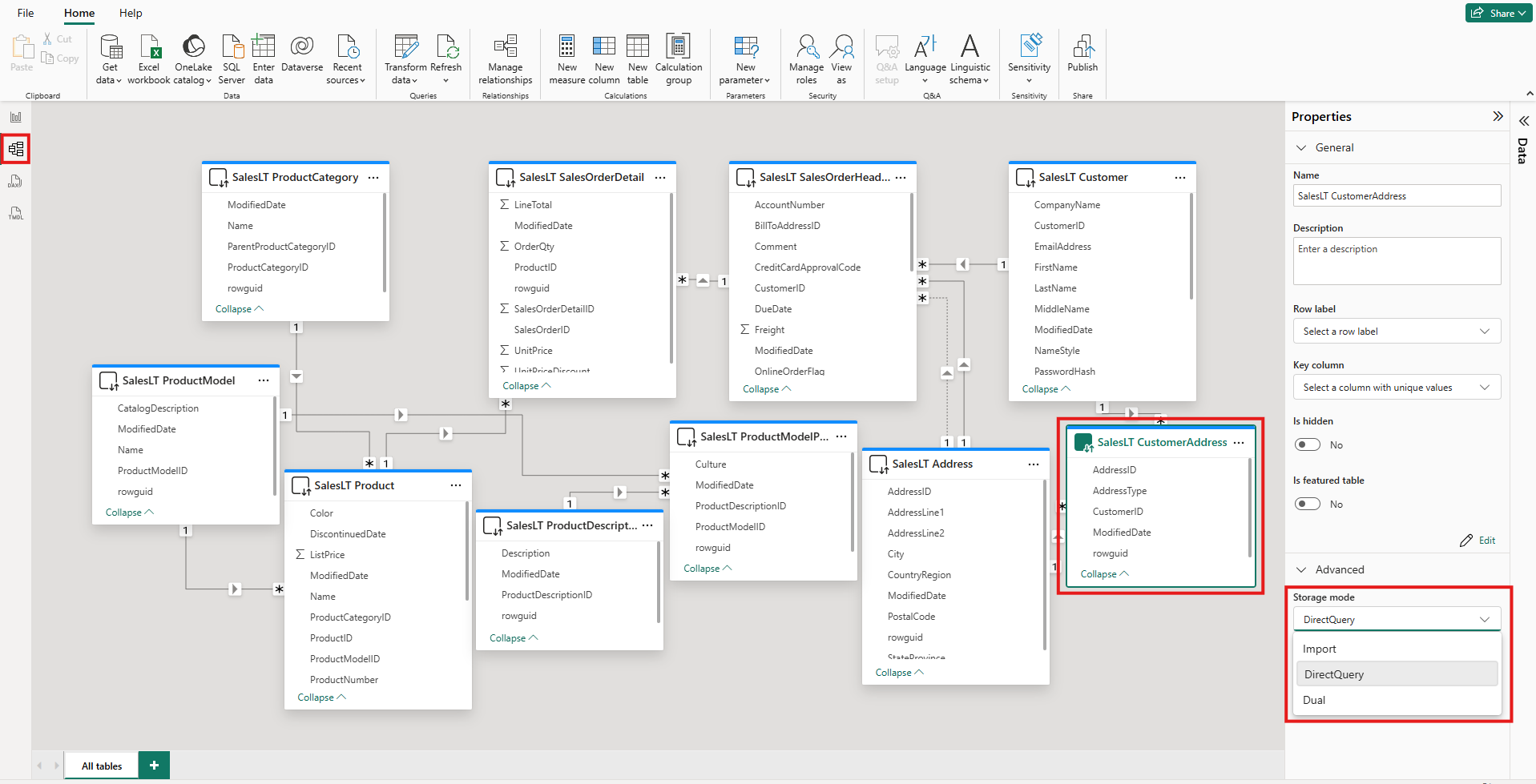
Una tabla agregada (Import) por mes-producto responde al instante; el detalle DQ solo se toca si hace falta.
-- Vista agregada que ya trae la BD de SunFruitsSELECT periodo, producto_id, SUM(monto_usd), SUM(kg_netos)
FROM vw_ventas_agg_mes; -- ~419 filas vs 4000+ del detalle
Configúrala en Administrar agregaciones mapeando al detalle DQ.
Reducir cardinalidad
Caro
IDs/textos largos como clave
datetime con segundos
Decimales con muchos dígitos
Columnas que nadie usa
Eficiente
Claves enteras (surrogate)
Separar fecha y hora
Redondear lo razonable
Quitar columnas sin uso
Menos valores distintos = mejor compresión y consultas más rápidas.
Relaciones e integridad referencial
Dirección de filtro Única; evita bidireccional en DirectQuery.
En relaciones DQ activa "Asumir integridad referencial": usa INNER JOIN (más rápido) en vez de OUTER.
Requisito: no debe haber claves huérfanas (en SunFruits las FK lo garantizan).
Nuestra BD define FOREIGN KEY en fact_ventas → integridad garantizada para activar esta opción sin perder filas.
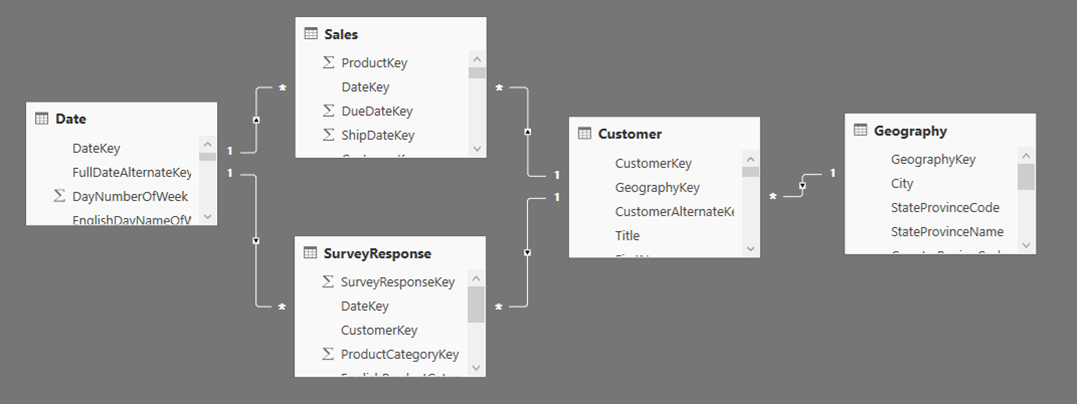
Arquitectura recomendada (SunFruits)
Vista Modelo · Microsoft Learn
fact_ventas → DirectQuery
dim_cliente, dim_producto → Dual
dim_fundo, Calendario → Import
Agregado mes-producto → Import
Frescura donde importa, velocidad donde se consulta.
Buenas prácticas
En el origen
Vistas limpias y con índices
Tipos correctos y claves enteras
Tabla/vista agregada
En Power BI
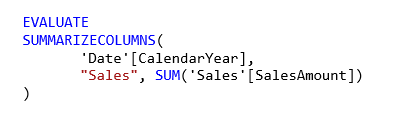
Verifica folding (consulta nativa)
Storage mode pensado por tabla
Integridad referencial asumida
Mide el SQL generado
🛠 Taller de la sesión
Parte 1 — Conectar
Conecta a la BD sunfruits (vista vw_ventas) en DirectQuery.
Importa dimensiones; marca compartidas como Dual.
Parte 2 — Optimizar
Verifica folding con "Ver consulta nativa".
Configura la agregación con vw_ventas_agg_mes.
Activa integridad referencial en las relaciones.
Resumen — puntos importantes
🅰 Modos
Import (memoria) vs DirectQuery (en vivo) vs Dual
Modelo compuesto = lo mejor de ambos
Hecho en DQ, dimensiones Import/Dual
🅱 Optimización
Query folding empuja al origen
Lógica en vistas SQL
Agregaciones para hechos grandes
Cardinalidad e integridad referencial
🎯 Una idea: que el servidor haga el trabajo. Power BI pide lo justo y muestra rápido.
Preguntas de repaso
Verifiquemos lo aprendido en esta sesión
1
¿Cuándo elegirías DirectQuery en lugar de Import?
2
¿Para qué sirve el modo Dual en un modelo compuesto?
3
¿Qué es el query folding y cómo verificas que ocurre?
4
¿Qué problema resuelven las agregaciones en DirectQuery?
5
¿Por qué conviene "asumir integridad referencial" en relaciones DQ?
Sun Fruits Exports · Programa Power BI
¡Gracias!
Gracias al equipo de SunFruits por su tiempo y participación
Edwin Barrientos Retuerto
Arquitecto de Inteligencia de Negocios & Cloud · Instructor
🌐 blog.arquitecturabi.pe
Nos vemos en la Sesión 6 — DAX avanzado e inteligencia de tiempo